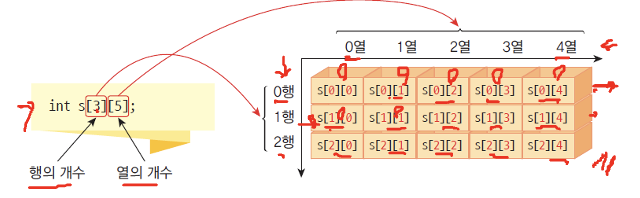
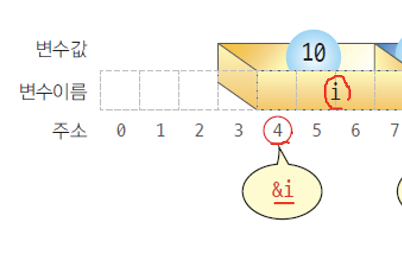
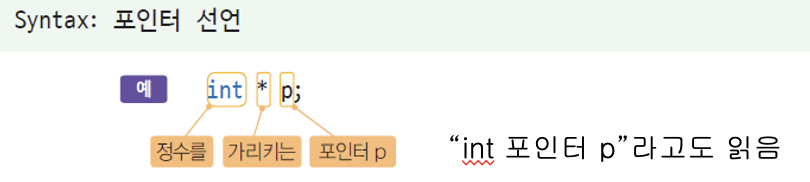
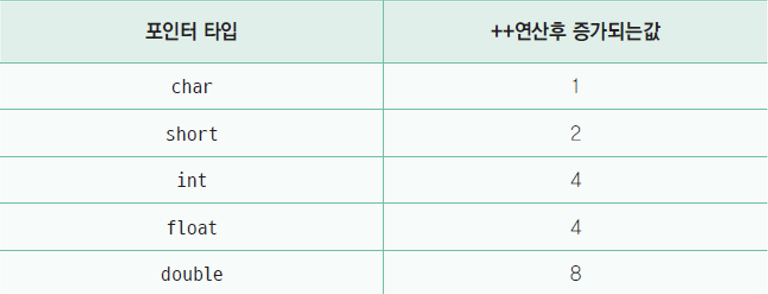
자료형
- 기초 자료형 int, double 이런거
- 파생 자료형 포인터, 구조체
- 사용자 정의 자료형 typedef enum
구조체가 필요한 이유?
서로 다른 자료형의 개별변수를 묶는 방법이 바로 구조체임

구조체와 배열의 다른점은?
배열은 같은 자료형이고
구조체는 서로 다른형을 묶을수있음
구조체 선언

구조체 선언은 변수 선언은 아님
구조체를 정의하는 것은 와플이나 붕어빵을 만드는 틀을 정의하는것임.
와플이나 붕어빵을 실제로 만들기위해서는 구조체 변수를 선언해야됌.
구조체 선언들
// x값과 y값으로 이루어지는 화면의 좌표
struct point {
int x; // x 좌표
int y; // y 좌표
};
// 복소수
struct complex {
double real; // 실수부
double imag; // 허수부
};
// 날짜
struct date {
int month;
int day;
int year;
};
// 사각형
struct rect {
int x;
int y;
int width;
int length;
};
// 직원
struct employee {
char name[20]; // 이름
int age; // 나이
int gender; // 성별
int salary; // 월급
};
구조체 정의와 구조체 변수 선언

중괄호를 이용하여 초기값을 나열함
struct student {
int number;
char name[10];
double grade;
}
struct student s1 = {24, "kim", 4.3};
구조체에서 멤버를 접근할때에는 . 을 사용하여서 접근함

struct student {
int number;
char name[10];
double grade;
};
int main(void)
{
struct student s; // 구조체 변수 선언
s.number = 201910794;
strcpy(s.name, "홍길동");
s.grade = 4.3;
printf("학번: %d\n", number);
printf("이름: $c\n", name);
pirntf("학점": %f\n", grade);
return 0;
}출력결과
학번: 201910794
이름: 홍길동
학점: 4.3
구조체를 멤버로 가지는 구조체
struct date {
int year:
int month;
int day;
}
struct student {
int number;
char name[10];
struct date dob; //구조체 안에 구조체 포함
double grade;
};
struct student s1;
s1.dob.year = 1983;
s1.dob.month =3;
s1.dob.day = 29;
같은 구조체 변수끼리 대입은 가능하지만 비교는 불가능
struct point {
int x;
int y;
};
int main(void)
{
struct point p1 = {10, 20};
struct point p2 = {30, 40};
p2 = p1; // 대입 가능(메모리 복사)
if( p1 == p2 ) // 비교 -> 컴파일 오류!!( 변수 비교)
printf("p1와 p2이 같습니다.")
if( (p1.x == p2.x) && (p1.y == p2.y) ) // 올바른 비교( 멤버 비교)
printf("p1와 p2이 같습니다.")
}변수의 멤버까지 들어가서 비교를 해야됌
구조체 배열이란?
같은 구조체를 여러개 모은것
struct student {
int number;
char name[10];
double grade;
};
int main(void)
{
struct student list[100]; // 구조체의 배열 선언
list[2].number = 24;
strcpy(list[2].name, "홍길동");
list[2].grade = 4.3;
}
구조체 배열의 초기화
struct student list[3] = {
{ 1, "Park", 3.42 },
{ 2, "Kim", 4.31 },
{ 3, "Lee", 2.98 }
};
이런식으로 구조체 배열에 입력값을 넣어줄수있음
#define SIZE 3
struct student {
int number;
char name[20];
double grade;
};
int main(void)
{
struct student list[SIZE];
int i;
for(i = 0; i < SIZE; i++)
{
printf("학번을 입력하시오: ");
scanf("%d", &list[i].number);
printf("이름을 입력하시오: ");
scanf("%s", list[i].name);
printf("학점을 입력하시오(실수): ");
scanf("%lf", &list[i].grade);
}
for(i = 0; i< SIZE; i++)
printf("학번: %d, 이름: %s, 학점: %f\n", list[i].number, list[i].name, list[i].grade);
return 0;
}
구조체와 포인터
구조체를 가리키는 포인터
struct student s = {24, "kim", 4.3};
struct student *p;
p = &s;
printf("학번=%d 이름=%s 학점=%f \n", s.number, s.name, s.grade);
printf("학번=%d 이름=%s 학점=%f \n", (*p).number, (*p).name, (*p).grade);
printf("학번=%d 이름=%s 학점=%f \n", p->number, p->name, p->grade); // ->연산자는 구조체 포인터로 구조체 멤버를 접근할때 사용
-> 연산자
(*p).number = p가 가리키는 구조체 변수의 멤버 number
p -> number = p가 가리키는 구조체 변수의 멤버 number
// 포인터를 통한 구조체 참조
#include <stdio.h>
struct student {
int number;
char name[20];
double grade;
};
int main(void)
{
struct student s = { 20070001, "홍길동", 4.3 };
struct student *p;
p = &s;
printf("학번=%d 이름=%s 학점=%f \n", s.number, s.name, s.grade);
printf("학번=%d 이름=%s 학점=%f \n", (*p).number,(*p).name,(*p).grade);
printf("학번=%d 이름=%s 학점=%f \n", p->number, p->name, p->grade);
return 0;
}결과는 모두 다 동일하게 나옴
포인터를 멤버로 가지는 구조체
struct date {
int month;
int day;
int year;
};
struct student {
int number;
char name[20];
double grade;
struct date *dob; //포인터를 멤버로 가짐
};
int main(void)
{
struct date d = { 3, 20, 1990 };
struct student s = { 20190001, "Kim", 4.3 };
s.dob = &d;
printf("학번: %d\n", s.number);
printf("이름: %s\n", s.name);
printf("학점: %f\n", s.grade);
printf("생년월일: %d년 %d월 %d일\n", s.dob->year, s.dob->month, s.dob->day);
return 0;
}
구조체 변수를 함수의 인수로 전달하는 경우에는 구조체의 복사본이 함수로 전달됨
따라서, 함수에서 새로운 구조체 변수가 만들어져서 구조체 멤버가 복사되는거임
구조체 크기가 크면 그만큼 시간과 메모리가 소요됨.
구조체 포인터를 함수의 인수로 전달하는 경우에는 구조체의 주소가 전달됨
시간과 공간 절약할수있지만 원본 훼손의 가능성이 있음

구조체를 반환하는 경우
struct student create() {
struct student s;
s.number = 3;
strcpy(s.name, “park”);
s.grade = 5.0;
return s;
}
int main(void) {
struct student a;
a= create();
return 0;
}이렇게 하면 복사본이 반환됨(구조체 변수 s가 변수 a로 복사)
void create(struct student *p) {
p->number = 3;
strcpy(p->name, “park”);
p->grade = 5.0;
}
int main(void) {
struct student a;
create(&a);
return 0;
}이렇게하면 주소가 반환됨(구조체 포인터 변수 p를 사용하여 변수 a값 변경)
공용체 - 같은 메모리 영역을 여러개의 변수가 공유, 공용체를 선언하고 사용하는 방법은 구조체와 비슷
union example {
char c; // 같은 공간 공유
int i; // 같은 공간 공유
};공용체의 메모리 크기는 멤버중 가장 큰 크기
#include <stdio.h>
union example {
int i;
char c;
};
int main(void)
{
union example v;
v.c = 'A';
printf("v.c:%c v.i:%i\n", v.c, v.i );
v.i = 10000;
printf("v.c:%c v.i:%i\n", v.c, v.i);
}
이렇게하면 출력값은
v.c:A v.i:-858993599
v.c:† v.i:10000
이렇게 나오게되는데 왜 두번째 값의 결과가 저렇게 나올까하고 찾아보니
공용체의 특성 때문임
공용체는 여러멤버가 같은 메모리 위치를 공유하게되는데 이는 모든 멤버가 메모리의 시작 위치를 공유한다는 의미.
따라서 하나의 멤버에 값을 할당하면 다른 멤버들도 같은 메모리를 바라보게됨.
공용체에 대한 타입 필드 사용
#include <stdio.h>
#include <string.h>
#define STU_NUMBER 1
#define REG_NUMBER 2
struct student {
int type;
union {
int stu_number; // 학번
char reg_number[15]; // 주민등록번호
} id;
char name[20];
};
void print(struct student s)
{
switch(s.type)
{
case STU_NUMBER:
printf("학번 %d\n", s.id.stu_number);
printf("이름: %s\n", s.name);
break;
case REG_NUMBER:
printf("주민등록번호: %s\n", s.id.reg_number);
printf("이름: %s\n", s.name);
break;
default:
printf("타입오류\n");
break;
}
}공용체는 저 두개를 다 사용하지않을때만 사용해야됌 만약 두개를 다 사용해야한다하면 공용체를 쓰면안댐
#define STU_NUMBER 1
#define REG_NUMBER 2
struct student {
int type;
union {
int stu_number;
char reg_number[15];
} id;
char name[20];
};
int main(void)
{
struct student s1, s2;
s1.type = STU_NUMBER;
s1.id.stu_number = 20190001;
strcpy(s1.name, "홍길동");
s2.type = REG_NUMBER;
strcpy(s2.id.reg_number, "860101-1056076");
strcpy(s2.name, "김철수");
print(s1);
print(s2);
}공용체는 이렇게 타입별로 나눠서 쓸수있음. 단 두개를 동시에쓰면안댐
열거형 - 변수가 가질 수 있는 값들을 미리 열거해 놓은 자료형
예시) 요일을 저장하고있는 변수는 {일요일, 월요일, 화요일, 수요일, 목요일, 금요일, 토요일}중의 하나의 값만
가질 수 있다
열거형의 선언
enum days {SUN, MON, TUE, WED, THU, FRI, SAT};
열거형의 변수 선언
enum days today;
today = SUN;
열거형 안에있는 기호상수값만 사용할수있어서 프로그램의 오류를 막아줌
열거형이 필요한이유?
- 오류를 줄이고 가독성을 높힘, 기호상수라 의미를 좀 더 쉽게 알수있기때문
열거형의 초기화
enum days { SUN, MON, TUE, WED, THU, FRI, SAT }; // SUN=0, MON=1, ...
enum days { SUN=1, MON, TUE, WED, THU, FRI, SAT }; // SUN=1, MON=2, ...
enum days { SUN=7, MON=1, TUE, WED, THU, FRI, SAT=6 };// SUN=7, MON=1, ...만약 값을 지정하지 않으면 0부터 시작함
#include <stdio.h>
enum days { SUN, MON, TUE, WED, THU, FRI, SAT };
char *days_name[] = {
"sunday", "monday", "tuesday", "wednesday", "thursday", "friday",
"saturday" };
int main(void)
{
enum days d;
d = WED;
printf("%d번째 요일은 %s입니다\n", d, days_name[d]);
return 0;
}출력값:
3번째 요일은 wednesday입니다
기호상수값이 출력되는게아님 프로그램 내에서 컴파일에서 3을 대표하는 값으로 사용하고있는것임

정수형: 사람이 기억하기 어려움
기호 상수: 오타날수있음
열거형: 컴파일러가 열거형 멤버 이외의 것을 방지함
typedef의 개념
- typedef는 기본 자료형에 새로운 자료형을 추가한것

typedef unsigned char BYTE;
BYTE index; // unsigned char index;와 같다.
typedef int INT32;
typedef unsigned int UINT32;
INT32 i; // int i;와 같다.
UINT32 k; // unsigned int k;와 같다.
구조체로 새로운 타입을 정의할 수 있음
struct point {
int x;
int y;
};
typedef struct point POINT;
POINT a, b;
typedef float VECTOR[2];
- VECTOR은 실수 2개로 이루어진 1차원 배열
typedef int MATRIX[10][10];
- MATRIX는 정수 100개로 이루어진 2차원 배열
typedef와 #define 비교
typedef쓰는이유?
이식성(오류가 안남)을 높혀줌.
코드를 컴퓨터 하드웨어에 독립적으로 만들수있음
- int형은 2바이트이기도 하고 4바이트, int형 대신에 typedef을 이용한 INT32나 INT16을 사용하게 되면 확실하게 2바이트인지 4바이트인지를 지정할 수 있다.
포인터의 활용
이중포인터: 포인터를 가리키는 포인터
int i = 10; // i는 int형 변수
int *p = &i; // p는 i를 카리키는 포인터
int **q = &p; // q는 포인터p를 가리키는 이중 포인터

이중포인터의 해석

*q는 p와 동일함
*p, **q는 i와 동일함
// 이중 포인터 프로그램
#include <stdio.h>
int main(void)
{
int i = 100;
int *p = &i;
int **q = &p;
*p = 200;
printf("i=%d\n", i);
**q = 300;
printf("i=%d\n", i);
return 0;
}출력값:
i=200
i=300
#include <stdio.h>
void set_pointer(char **q);
int main(void)
{
char *p;
set_pointer(&p);
printf("오늘의 격언: %s \n", p);
return 0;
}
void set_pointer(char **q)
{
*q = "All that glisters is not gold.";
}**q = &p
*q와 p가 같음
따라서 출력값은
오늘의 격언: All that glisters is not gold
포인터 배열이란? 포인터를 모아서 배열로 만든것


int *ap[10]는 이런 배열이 된다
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| int* | int* | int* | int* | int* | int* | int* | int* | int* | int* |
정수형 포인터배열
int a = 10, b = 20, c = 30, d = 40, e = 50;
int* api[5] = { &a, &b, &c, &d, &e };

이런식으로 포인터가 지정됨.
2차원배열을 사용하여서 문자열을 저장하면 밑에 그림처럼 낭비되는 공간이 생성됨.
char fruits[4 ][10] = {
"apple",
"blueberry",
"orange",
“melon"
};

문자형 포인터 배열을 ragged배열 이라고함
char* fruits[ ] = {
"apple",
"blueberry",
"orange",
“melon"
};
이렇게하면 가변배열이라서 낭비되는공간이 없음

#include <stdio.h>
int main(void)
{
int i, n;
char* fruits[ ] = {
"apple",
"blueberry",
"orange",
"melon"
};
n = sizeof(fruits)/sizeof(fruits[0]); // 배열 원소 개수 계산
for(i = 0; i < n; i++)
printf("%s \n", fruits[i]);
return 0;
}이렇게 배열의 크기를 구해서 반복문으로 출력하면 출력값은
apple
blueberry
orange
melon
배열 포인터란? 배열을 가리키는 포인터임

아까 포인터배열이랑 헷갈리면 안됌

포인터배열과 배열포인터 비교
포인터 배열은 포인터를 원소로하는 배열을 만든것

배열 포인터는 기본형을 원소로하는 배열을 가리키는 포인터

#include <stdio.h>
int main(void)
{ int i, j;
int a[2][3] = {
{1, 2, 3},
{4, 5, 6} };
int* ap[2];
for (i = 0; i < 2; i++) {
ap[i] = a[i];
for (j = 0; j < 3; j++)
printf("%d ", ap[i][j]);
printf("\n");
}
printf("\n");
for (i = 0; i < 2; i++) {
for (j = 0; j < 3; j++)
printf("%d ", (*(ap+i))[j]);
printf("\n");
}
printf("\n");
}
int(*pa)[3];
pa = a;
for (i = 0; i < 2; i++) {
for (j = 0; j < 3; j++)
printf("%d ", pa[i][j]);
printf("\n");
}
printf("\n");
for (i = 0; i < 2; i++) {
for (j = 0; j < 3; j++)
printf("%d ", (*pa)[j]);
printf("\n");
pa++;
}
return 0;
}이거 이해하고 넘어가기
아직 이해는 못함
함수 포인터: 함수를 가리키는 포인터


#include <stdio.h>
// 함수 원형 정의
int add(int, int);
int sub(int, int);
int main(void)
{
int result;
int (*pf)(int, int); // 함수 포인터 정의
pf = add; // 함수 포인터에 함수 add()의 주소 대입
result = pf(10, 20); // 함수 포인터를 통한 함수 add() 호출
printf("10+20은 %d\n", result);
pf = sub; // 함수 포인터에 함수 sub()의 주소 대입
result = pf(10, 20); // 함수 포인터를 통한 함수 sub() 호출
printf("10-20은 %d\n", result);
return 0;
}
int add(int x, int y)
{
return x+y;
}
int sub(int x, int y)
{
return x-y;
}
결과값:
10+20은 30
10-20은 -10
포인터함수는 반드시 *pf에서 괄호먼저 써줘야됌
함수 포인터의 배열
int (*pf[5]) (int, int);

배열이 *보다 우선순위가 높으므로 이건 포인터들의 배열임 근데 이 포인터들의 배열이 함수 포인터가 됨.

이렇게 배열안에있는 포인터들이 함수 포인터가됨.
// 함수 포인터 배열
#include <stdio.h>
// 함수 원형 정의
void menu(void);
int add(int x, int y);
int sub(int x, int y);
int mul(int x, int y);
int div(int x, int y);
void menu(void)
{
printf("=====================\n");
printf("0. 덧셈\n");
printf("1. 뺄셈\n");
printf("2. 곱셈\n");
printf("3. 나눗셈\n");
printf("4. 종료\n");
printf("=====================\n");
}
int main(void)
{
int choice, result, x, y;
// 함수 포인터 배열을 선언하고 초기화한다.
int (*pf[4])(int, int) = { add, sub, mul, div };
while(1)
{
menu();
printf("메뉴를 선택하시오:");
scanf("%d", &choice);
if( choice < 0 || choice >=4 )
break;
printf("2개의 정수를 입력하시오:");
scanf("%d %d", &x, &y);
result = pf[choice](x, y); // 함수 포인터를 이용한 함수 호출
printf("연산 결과 = %d\n",result);
}
return 0;
}
int add(int x, int y)
{
return x + y;
}
int sub(int x, int y)
{
return x - y;
}
int mul(int x, int y)
{
return x * y;
}
int div(int x, int y)
{
return x / y;
}
이렇게 함수 포인터를
int (*pf[4])(int,int) = {add, sub, mul, div} 로 하여서 계산할수있다
함수 포인터도 인수로 전달이 가능함.
다차원 배열과 포인터
2차원 배열 int m[3][3]
1행 > 2행 > 3행 > 순으로 메모리에 저장됨(행 우선방법)
같은 행 내에서는 열순서로 저장됨
#include <stdio.h>
int main(void)
{
int m[3][3] = { 10, 20, 30, 40, 50, 60, 70, 80, 90 };
printf("m = %p\n", m); //%p ->%u
printf("m[0] = %p\n", m[0]);
printf("m[1] = %p\n", m[1]);
printf("m[2] = %p\n", m[2]);
printf("&m[0][0] = %p\n", &m[0][0]);
printf("&m[1][0] = %p\n", &m[1][0]);
printf("&m[2][0] = %p\n", &m[2][0]);
return 0;
}m = 1245020
m[0] = 1245020
m[1] = 1245032
m[2] = 1245044
&m[0][0] = 1245020
&m[1][0] = 1245032
&m[2][0] = 1245044
여기서 결과값이 이렇게 나오는데 저 %p라는 것은 배열의 주소를 출력함 근데 우리가 보기 편하게 %u로 해서 주소를 찍어봤는데
m을 찍으면 1245020이라는 값이 나오는데 이건 배열의 시작 주소임(m의 시작주소)
그럼 int형은 4바이트니까 3x3배열이니 m[1]을 찍으면 첫 배열 시작주소(m[0])보다 4*3을 더한 1245032
라는 값이 나옴 마찬가지로 또 m[2]을 찍어보면 거기서 12를 더한 주소 값이 출력됨
그 밑에있는 것들도 마찬가지로 그렇게 주소값이 찍힘
m[0]은 배열 m의 1행의 시작 주소이며 m[1]은 배열 m의 2행의 시작주소임

int m[3][3]; *와 [] 연산자는 1:1 대응
- 2차원(행) 원소
m: int[][]형 m의 주소, m[0]:int[]형, m[0]의 주소, m[0][0]:int 값
m+1:int[][] =>m+1= &*(m+1)= &m[1]
*(m+1), m[1]:int[] => *(m+1)= m[1], m[1]= *(m+1)
(m+1)[0]:int[] =>(m+1)[0]= *(m+1+0)= m[1]
(m+1)[1]= *((m+1)+1)= m[2]
*(m+1)[1]= *((m+1)[1])= *(*(m+1+1))= *(m[2])= m[2][0]
(*(m+1))[1]= m[1][1]
*(m[1]+2)= m[1][2]
*m[1]+2 = m[1][0]+2
아잠만 이거 이해 안되네 뭐지
아 이거 *(m+1)은 m[1]이라고 생각하고 배열이랑 포인터 같이있으면 포인터에 괄호가 쳐져있지않는이상
배열이 먼저임 그래서 (m+1)[1]이면 그냥 더해 그래서 m[2]이렇게 되는거 외우고 (*(m+1))[1] 이렇게 되어있으면
포인터먼저니까 m[1][1]이렇게댐
걍 다 외우자...
행의 평균을 구해보자면
#define ROWS 3
#define COLS 3
double get_row_avg(int m[][COLS], int r)
{
int *p, *endp;
double sum = 0.0;
p = &m[r][0]; //m[r]+0
endp = &m[r][COLS];//m[r]+COLS
while( p < endp )
sum += *p++;
sum /= COLS;
return sum;
}
이 밑에있는 그림을 참고해서 해보자
우선 포인터로 p랑 endp라는 포인터 변수를 선언
그리고 행의 평균을 구하려면 합이있어야돼서 sum 실수도 선언
그럼 포인터 p에 배열m의 입력받아서 평균을 구해줄 행의 수인 r행과 연결시켜줘r행의 첫번째 인덱스 0 이겠지?
근데 걍 m[r]이라고 해도 노상관.
그리고 endp라는 포인터변수에 cols를 저기서 전역변수값으로 3을줬자나 그걸 넣어주고 r값을 행에넣어주면
저 endp의 주소는 r행의 마지막 인덱스에서 한나 더 플러스된곳의 주소자나
그리고 이제 p는 주소값이지? *p면 저 배열이랑 연결되어있으니까 배열안의 값인데 그냥 p는 주소값이자나
그럼 결과적으로 p에는 r행의 첫번째 인덱스의 주소값이 들어가있고
endp에는 r행의 마지막 인덱스보다 한 인덱스 더 뒤에있는 인덱스의 주소값이 들어있게된거자나
그럼 r행의 배열의 총 합을 구하려면
저 r행렬들을 다 더해야되자나 근데 아까 행렬들의 주소값을 살펴봤을때 행은 위에서부터 아래로 열은 왼에서 오로 갈수록 주소값이
더 커진다했지 그래서 그걸 이용해서 while문으로 p가 endp보다 작을때동안
sum이라는 변수에 *p(p가 아니라 *p니까 배열안에있는 값)값을 더하고 p의 값을 ++한다(주소인p를 ++함으로서 다음 인덱스로 넘어간다) 를 반복해버리면 저 행렬들안에있는 모든 값들을 더한 sum값이 구해지겠지
그럼 그 총 합값을 열의 크기인 cols로 나눠주면 저 행의 값들의 평균이 나오겠찌!!!!
그럼 한번 전체원소의 평균을 구해보자
#define ROWS 4
#define COLS 3
double get_total_avg(int m[][COLS])
{
int *p, *endp;
double sum = 0.0;
p = &m[0][0];//p=*m, m[0]
endp = &m[ROWS-1][COLS];
while( p < endp )
sum += *p++;
sum /= ROWS * COLS;
return sum;
}
아까와 마찬가지로 포인터 변수 두개 선언해주고 p에
배열의 첫번째 인덱스 주소 연결해주고 endp에 배열의 마지막 인덱스 주소 연결해주기
그리고 p가 endp보다 작을때동안 sum에 *p의 값들을 넣어주고 하나씩 주소를 더해서 옮기는걸해줌
sum += *p++;
그 후 다 더한 sum값을 rows*cols로 나눠줌
그럼 전체 배열원소의 평균값을 구할수있음
const 포인터
const를 붙이는 위치에 따라서 의미가 달라진다.
const char *p; 는 p가 가리키는 내용이 변경되지 않음을 나타낸다
char *const p; 는 포인터 p가 변경되지않음을 나타냄;

volatile 포인터
volatile은 다른 프로세스나 스레드가 값을 항상 변경할 수 있으니 값을 사용할때마다 다시 메모리에서 읽으라는 것을 의미함

void 포인터(제네릭 포인터)
순수하게 메모리의 주소만 가지고있는 포인터
가리키는 대상물은 아직 정해지지않음
예) void *vp;
*vp;, vp++; vp--; 같은 모든 연산은 오류임.
*(int *)vp;
//void형 포인터를 Int형 포인터로 변환함.
그럼 이러한 void 포인터는 어디에 사용하는가?
void 포인터를 이용하면 어떤 타입의 포인터도 받을수있는 함수를 작성할수있음
main()함수의 인수
지금까지의 main 함수의 형태는
int main(void) {
.
.
}
이런 형태였음
근데 외부로부터 입력을 받는 main()함수의 형태는
int main(int argc, char *argv[])
{
.
.
}
이런 형태임
인수 전달 방법
C: \cprogram> mycopy src dst

#include <stdio.h>
int main(int argc, char *argv[])
{
int i = 0;
for(i = 0;i < argc; i++)
printf("명령어 라인에서 %d번째 문자열 = %s\n", i, argv[i]);
return 0;
}출력값:
c:\cprogram\mainarg\Debug>mainarg src dst
명령어 라인에서 0번째 문자열 = mainarg
명령어 라인에서 1번째 문자열 = src
명령어 라인에서 2번째 문자열 = dst
c:\cprogram\mainarg\Debug>
mile2km.c
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
double mile, km;
if( argc != 2 ){
printf("사용 방법: mile2km 거리\n");
return 1;
}
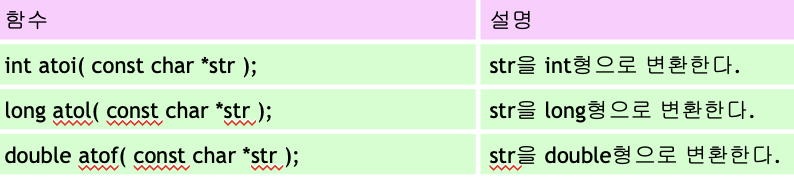
mile = atof(argv[1]);
km = 1.609 * mile;
printf("입력된 거리는 %f km입니다. \n", km);
return 0;
}출력값:
e:>mile2km 10
입력된 거리는 16.090000 km입니다.
lab: qsort() 함수 사용하기
qsort()는 데이터가 저장된 배열을 정렬하는데 사용되는 라이브러리 함수이다.
void qsort(void *base, size_t nitems, size_t size, int (*compare)(const void*, const void*));
base: 정렬될 배열의 주소
nitems: 원소들의 개수(배열의 크기)
size: 각 원소들의 크기(바이트 단위)
compare: 2개의 원소를 비교하는 함수
#include <stdio.h>
#include <stdlib.h>
int values[] = { 98, 23, 99, 37, 16 };
int compare(const void * a, const void * b) {
return (*(int*)a - *(int*)b);
}
int main() {
int n;
qsort(values, 5, sizeof(int), compare);
printf("정렬한 후 배열: ");
for (n = 0; n < 5; n++)
printf("%d ", values[n]);
printf("\n");
return(0);
}
출력값:
정렬한 후 배열: 16 23 37 98 99
계속하려면 아무 키나 누르십시오 . . .
스트림이랑 파일같은것들...
#include <stdio.h>
int main( void )
{
if( remove( "sample.txt" ) == -1 )
printf( "sample.txt를 삭제할 수 없습니다.\n" );
else
printf( "sample.txt를 삭제하였습니다.\n" );
return 0;
}여기서 remove를 했는데 -1이면 삭제를 못했다뜻임
기타 함수들

파일의 입출력함수

#include <stdio.h>
int main(void)
{
FILE *fp = NULL;
fp = fopen("sample.txt", "w");
if( fp == NULL )
printf("파일 열기 실패\n");
else
printf("파일 열기 성공\n");
fputc('a', fp);
fputc('b', fp);
fputc('c', fp);
fclose(fp);
return 0;
}이 코드에서는 sample.txt가 존재한다는걸 기준으로 하였으므로
출력값은
파일 열기 성공
sample.txt안에있는 값은: abc
#include <stdio.h>
int main(void)
{
FILE *fp = NULL;
int c;
fp = fopen("sample.txt", "r");
if( fp == NULL )
printf("파일 열기 실패\n");
else
printf("파일 열기 성공\n");
while((c = fgetc(fp)) != EOF )
putchar(c);
fclose(fp);
return 0;
}fgetc를 이용하여서 파일이 eof즉 -1 정보가 없기전까지 하나씩 c에 넣어서 putchar로 c를 출력하는것이다
gets_s, puts, fgets_s, fputs
gets_s(): 표준 입력에서 문자들을 개행문자('\n')이나 파일 끝 (eof)를 만나기 전까지 가져와서 str에 저장함
개행문자는 문자열에 포함되지않으며 대신 널문자('\0')는 문자열 맨 마지막에 자동적으로 추가된다.
puts(): 표준 출력(stdout)에 쓴뒤 자동으로 개행문자 ('\n')도 추가
fgets_s(): 개행문자는 문자열에 포함된다.
fputs(): 자동으로 개행문자도 추가되지 않는다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
FILE *fp1, *fp2;
char file1[100], file2[100];
char buffer[100];
printf("원본 파일 이름: ");
scanf("%s", file1);
printf("복사 파일 이름: ");
scanf("%s", file2);
// 첫번째 파일을 읽기 모드로 연다.
if( (fp1 = fopen(file1, "r")) == NULL )
{
fprintf(stderr,"원본 파일 %s을 열 수 없습니다.\n", file1);
exit(1);
}
// 두번째 파일을 쓰기 모드로 연다.
if( (fp2 = fopen(file2, "w")) == NULL )
{
fprintf(stderr,"복사 파일 %s을 열 수 없습니다.\n", file2);
exit(1);
}
// 첫번째 파일을 두번째 파일로 복사한다.
while( fgets(buffer, 100, fp1) != NULL )
fputs(buffer, fp2);
fclose(fp1);
fclose(fp2);
return 0;
}출력값:
원본 파일 이름: a.txt
복사 파일 이름: b.txt
이거는 a파일을 b파일로 복사하는건데
a파일은 읽기모드로 열고 b파일은 쓰기모드로 연다 물론 각각의 경우에대해서 null이라면 열수없다고 출력하고
프로그램이 종료되게해준다
이상없이 두 파일이 다 열렸다면 while문을 통하여 최대 100자까지 버퍼에 쏜다그후 쓰기파일에 있는 그대로
문자를 적는다.
슬라이드 30페이지 부터
이진파일의 쓰기와 읽기
이진 파일의 예시

이진 파일의 모드

이진파일을 쓰려면?
fwrite()

일단여기까지하고
다음으로 넘어감
전처리 및 다중 소스파일
전처리기란? 컴파일하기에 앞서서 소스 파일을 처리하는 컴파일러의 한부분

| 지시어 | 의미 |
| #define | 매크로 정의 |
| #include | 파일 포함 |
| #undef | 매크로 정의 해제 |
| #if | 조건이 참일 경우 |
| #else | 조건이 거짓일 경우 |
| #endif | 조건 처리 문장 종료 |
| #ifdef | 매크로가 정의되어 있는 경우 |
| #ifndef | 매크로가 정의되어 있지 않은 경우 |
| #line | 행번호 출력 |
| #pragma | 시스템에 따라 의미가 다름 |
단순 매크로 정의
#define MAX_SIZE 100
: 기호상수 max_size를 100으로 정의한다.
단순 매크로의 장점
프로그램의 가독성을 높힌다, 상수 변경이 용이하다
단순 매크로의 예시
#define PI 3.141592 // 원주율
#define TWOPI (3.141592 * 2.0) // 원주율의 2배
#define MAX_INT 2147483647 // 최대정수
#define EOF (-1) // 파일의 끝표시
#define MAX_STUDENTS 2000 // 최대 학생수
#define EPS 1.0e-9 // 실수의 계산 한계
#define DIGITS "0123456789" // 문자 상수 정의
#define BRACKET "(){}[]" // 문자 상수 정의
#define getchar() getc(stdin) // stdio.h에 정의
#define putchar() putc(stdout) // stdio.h에 정의
#include <stdio.h>
#define AND &&
#define OR ||
#define NOT !
#define IS ==
#define ISNOT !=
int search(int list[], int n, int key)
{
int i = 0;
while( i < n AND list[i] != key )
i++;
if( i IS n )
return -1;
else
return i;
}
int main(void)
{
int m[] = { 1, 2, 3, 4, 5, 6, 7 };
printf("배열에서 5의 위치=%d\n", search(m, sizeof(m) / sizeof(int), 5));
return 0;
}
출력값:
배열에서 5의 위치=4
여기보면 단순 매크로로 사칙연산을 정의 해주고있다
함수 매크로란? 매크로가 함수처럼 매개 변수를 가지는 것
#define SQUARE(x) ((x) * (x))
#define SUM(x, y) ((x) + (y))
#define AVERAGE(x, y, z) (( (x) + (y) + (z) ) / 3 )
#define MAX(x,y) ( (x) > (y) ) ? (x) : (y)
#define MIN(x,y) ( (x) < (y) ) ? (x) : (y)
주의할점
1. 함수 매크로에서는 매개 변수를 괄호로 둘러싸는게 좋다
#define SQUARE(x) x*x // 위험 !!
v = SQUARE(a+b);
v = a + b*a + b;
이런식으로 의도한것과 다른 결과가 나올수있기때문
2. 매크로 이름과 괄호 사이에 공백이있으면 안된다
#define ADD (x, y) ((x)+(y))
이렇게 ADD랑 (x,y)사이에 공백이 있으면 ADD를 기호상수로 인식
장점
함수 호출 단계가 필요없어서 실행 속도가 빠르다.
매크로를 한줄 이상으로 연장하는 방법은?
#define PRINT(x) if( debug==1 && \
mode==1 ) \
printf(“%d”, x);
이런식으로 끝마다 \ 를 붙여주고 마지막엔 세미콜론
// 매크로 예제
#include <stdio.h>
#define SQUARE(x) ((x) * (x))
int main(void)
{
int x = 2;
printf("%d\n", SQUARE(x));
printf("%d\n", SQUARE(3));
printf("%f\n", SQUARE(1.2)); // 실수에도 적용 가능
printf("%d\n", SQUARE(x+3));
printf("%d\n", 100/SQUARE(x));
printf("%d\n", SQUARE(++x));
return 0;
}출력값:
4
9
1.440000
25
25
16
이런식으로 매크로 함수를 선언해준후 사용할땐 실수에도 적용이 가능하며 나누기도된다
#연산자
PRINT(x)와 같이 호출하면 x=5와 같이 출력하는 매크로 작성
다음과 같이 정의된 매크로를 살펴보자
#define PRINT(exp) printf(#exp " = %d\n", exp);
이 매크로는 매크로 호출시에 전달된 표현식 ('exp')를 문자열로 변환하여 출력하는 역할을 한다
예를들어서
int x = 10;
PRINT(x);
이렇게 매크로를 호출하면 전처리기는 #exp부분을 전달된 표현식('x')의 문자열로 변환함
따라서 실제 코드는 다음과같은 코드로 처리됨
printf("x=%d\n", x);
즉 #exp는 전달된 표현식을 큰 따옴표로 감싸 문자열로 변환하는 역할을 함. 이렇게하면
매크로가 호출될때 전달된 변수 또는 표현식의 이름을 출력할때 유용함
내장 매크로란? 미리 정의된 매크로
| 내장 매크로 | 설명 |
| __DATE__ | 이 매크로를 만나면 현재의 날짜(월 일 년)로 치환된다. |
| __TIME__ | 이 매크로를 만나면 현재의 시간(시:분:초)으로 치환된다. |
| __LINE__ | 이 매크로를 만나면 소스 파일에서의 현재의 라인 번호로 치환된다. |
| __FILE__ | 이 매크로를 만나면 소스 파일 이름으로 치환된다. |
printf("컴파일 날짜=%s\n", __DATE__);
printf("치명적 에러발생 파일이름=%s 라인 번호=%d\n", __FILE__, __LINE__);
이런식으로 사용할 수 있음.
assert()
디버깅 모드에서의 에러검출을함
단, 릴리즈 모드에서는 동작하지않음
#include <assert.h> 를 포함시켜야됌
assert(조건식) : 조건식이 false일때 assert() 호출 후 프로그램 종료됨.
#include <assert.h>
int main(void)
{
int score = -1;
assert(score > 0);
return 0;
}출력값:
Assertion failed: score > 0,
file C:\D\수업\C프로그램\prog\Project16\Project1\test.c, line 28
계속하려면 아무 키나 누르십시오 . . .
비트 관련 매크로
#include <stdio.h>
#define GET_BIT(w, k) (((w) >> (k)) & 0x01)
#define SET_BIT_ON(w, k) ((w) |= (0x01 << (k)))
#define SET_BIT_OFF(w, k) ((w) &= ~(0x01 << (k)))
int main(void)
{
int data=0;
SET_BIT_ON(data, 2);
printf("%08X\n", data);
printf("%d\n", GET_BIT(data, 2));
SET_BIT_OFF(data, 2);
printf("%08X\n", data);
printf("%d\n", GET_BIT(data, 2));
return 0;
}처음보면 어려울수있겠지만 생각해보면 쉬움
우선 매크로 함수를 살펴보면
GET_BIT(w,k) 함수는 주어진 정수 w의 k 번째 비트를 가져오는 매크로임.
SET_BIT_ON(w,k) 함수는 주어진 정수 w의 k번째 비트를 1로 설정하는 매크로임.
SET_BIT_OFF(w,k) 함수는 주어진 정수 w의 k번째 비트를 0로 설정하는 매크로임.
그럼 이제 main 함수를 살펴보자
우선 data를 0으로 초기화 시켜주고 setbiton을 사용하여서 data의 2번째 비트를 1로 만들고있음
근데 이게 2번째비트라고해서 뒤에서부터 2번째가아니라 2번 민다고 생각하면됨
즉 3번째 비트임.
그래서 이걸 16진수로 출력을 해주면
00000004라는 값이 나옴. 원래 00000000이였는데 두번 밀어서 세번째 비트를 1로 만들어서 00000100(=4)
저값을 16진수로 출력한거임.
그 후 getbit을 사용해서 data의 2번째 비트(2번밀린 비트 3번째)를 출력해보면 1이 나옴
그리고 setbitoff를 사용해서 data의 두번째 비트(3번째 비트)를 0으로 만들어주고
아까와 마찬가지로 16진수로 출력해보면 00000000 이렇게나옴 왜냐면 아까 1로된게 0으로되어서
다시 저렇게됨. 그 후 getbit을 사용해서 data의 2번째 비트(세번째 비트)를 출력해보면 0으로 바뀌어서 0이 출력됨.
#ifdef
#define DEBUG
int average(int x, int y)
{
#ifdef DEBUG
printf("x=%d , y=%d\n", x,y); //DEBUG가 정의되어있으니 컴파일에 포함
#endif
return (x+y)/2;
}
저 #ifdef뒤에 오는 DEBUG가 정의되어있으면 #ifdef와 #endif사이의 코드가 동작을한다
만약 DEBUG가 정의되어있지않으면 저 사이에있는 코드는 동작하지않는다.
이때 정의되는 DEBUG의 값은 상관이없다 그저 정의가 되었는지 안되어있는지가 중요하다.

이렇게 정의가되어있지않으면 저 사이의 코드가 동작안함.
#ifndef, #undef
#ifndef는 어떤 매크로가 정의되어있지않으면 코드가 동작하는거임 예를들어서 만약
LIMIT이라는게 정의되어있지않으면

이렇게 ifndef와 #endif사이의 코드가 돌아가니까 LIMIT를 정의해주는 방식으로 사용 가능
#undef는 매크로의 정의를 취소함.

#if
기호가 참으로 계산되면 사이의 코드가 동작됨.
조건은 정수 상수여야하고, 논리,관계연산자 사용가능함
실수나 문자열은 비교못함.
#if DEBUG==1
printf("value=%d\n",value);
#endif
이렇게 매크로 DEBUG의 값이 1이면 #if 와 #endif사이에 있는 코드들을 동작함.
정렬 알고리즘을 선택할때 유용함
#define SORT_METHOD 3
#if (SORT_METHOD == 1)
... // 선택정렬구현
#elif (SORT_METHOD == 2)
... // 버블정렬구현
#else
... // 퀵정렬구현
#endif이렇게 정의할때 매크로에 번호를 매겨서 정렬 알고리즘을 선택할수있음.
#if (AUTHOR == KIM) // 가능!! KIM은 다른 매크로
#if (VERSION*10 > 500 && LEVEL == BASIC) // 가능!!
#if (VERSION > 3.0) // 오류 !! 정수만 사용
#if (AUTHOR == "CHULSOO") // 오류 !! 실수나 문자열은 사용 못함
#if 0 을 사용하여서 주석처리를 할수도있음
#if 0 // 여기서부터 시작하여
void test()
{
/* 여기에 주석이 있다면 코드 전체를 주석 처리하는 것이 쉽지 않다. */
sub();
}
#endif // 여기까지 주석 처리된다.이렇게 if에 조건 대신 0을 넣어서 주석을 처리할수있음 #if와 #endif사이를 주석처리할수있음
다중 소스 파일
단일 소스 파일:
파일의 크기가 너무 커진다. 소스 파일을 다시 사용하기가 어렵다.
다중 소스 파일:
서로 관련된 코드만을 모아서 하나의 소스 파일로 할 수 있음
소스 파일을 재사용하기가 간편함.
헤더 파일을 사용하지않으면 함수원형 정의를 매번 있는대로 많이 써놔야됌

근데 헤더파일을 사용하게되면 간단해짐


비트 필드 구조체
구조체의 정수형의 멤버 변수를 비트단위로 나누어서 사용
: 사용 메모리 크기를 절약(내장 시스템)
정수형: (unsigned, signed) char, short, int, long
사용법:
struct tag {
정수형 변수명: 비트수;
}
멤버가 비트 단위로 나누어져있는 구조체
struct 태그이름 {
자료형 멤버이름1: 비트수;
자료형 멤버이름2: 비트수;
...
};
struct product {
unsigned style : 3;
unsigned size : 2;
unsigned color : 1;
};
비트 필드의 장점
메모리가 절약된다.
ON 또는 OFF의 상태만 가지는 변수를 저장할 때 32비트의 int형 변수를 사용하는 것보다는
1비트 크기의 비트 필드를 사용하는 편이 훨씬 메모리를 절약한다.