서버와 클라이언트가 각각 하나의 프로세스로써 어떻게 데이터를 주고 받는지 이해해보자.
IP주소와 포트번호
우선 컴퓨터가 네트워크 상에서 통신을 하기 위해서는 수많은 정보의 바다에서 자신이 누군지 유일하게 식별이 가능한 수단이 있어야한다.
-> 이때 사용되는 것이 IP주소(절대 겹치면 안되고, 고유해야함)
하지만 컴퓨터가 세상에 너무 많아지면서 자연스레 IP주소의 부족 현상이 발생함.
-> 이를 해결 하기 위하여 사설 IP주소를 사용하며 이를 공인 IP주소로 바꾸는 NAT, 서브네팅, IPv6등의 기술들이 나오게됨.
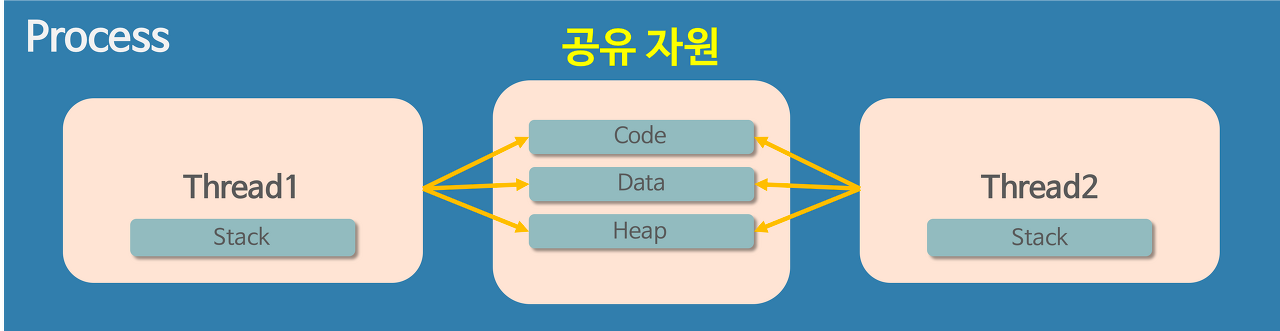
컴퓨터가 직접 네트워크에서 통신하는 것이 아니라, 컴퓨터에서 동작하는 프로세스가 또 다른 컴퓨터의 프로세스와 통신하는 것
프로세스간에 통신을 위해 IPC를 하되, 그저 다른 시스템의 프로세스와 IPC를 한다고 생각하는 것이 중요
IP주소를 통해 컴퓨터를 식별했다면, 해당 컴퓨터에서 어떤 프로세스에게 데이터를 보내야하는지 알아야하는데 이때 사용되는 식별값이 포트번호임.
클라이언트 a가 서버 b로 데이터를 보낼때 아래와 같은 형태로 데이터를 보낼 대상을 식별함
[서버 프로세스 B가 동작 중인 컴퓨터의 아이피 주소]:[서버 프로세스가 부여받은 포트번호]
즉, [203.230.7.2:80]의 뜻은 [203.230.7.2의 아이피 주소를 가진 컴퓨터의 80번 포트의 프로세스] 를 말한다.
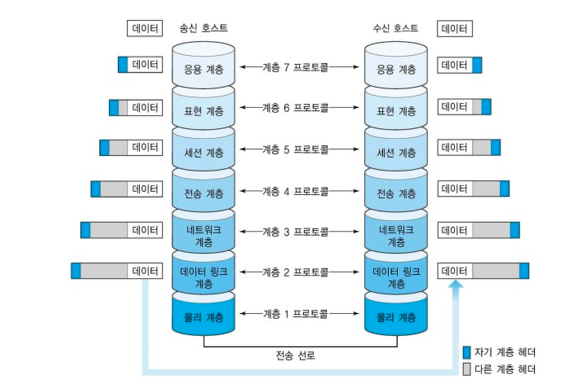
데이터 송신 과정
- Application (데이터를 송신 하려는 서버 프로세스)
- Sockets
- 네트워크 스택
- NIC
- 데이터 송신시
서버 프로세스가 운영체제의 write시스템 콜을 통해 소켓에 데이터를 보내게 되고 이후 tcp/udp계층과 ip계층 그리고 대표적으로 ethernet을 거쳐 흐름제어, 라우팅 등의 작업을 하게 된다.
이후 마지막으로 NIC를 통해 외부로 데이터를 보낸다.
- 데이터 수신시
데이터 수신시에는 반대로 NIC에서 데이터를 수신하고, 인터럽트를 통해 Driver로 데이터를 옮기고 이후 네트워크 스택에서 데이터가 이동하며 소켓에 데이터가 담기고, 최종적으로 수신 대상이 되는 프로세스에 데이터가 도달하게 된다.
TCP 전용 소켓(=stream 소켓)
tcp는 udp와 달리 신뢰성 있는 데이터 송수신을 하며 tcp 소켓을 활용하는 시스템 콜에서 이런 특징이 드러나게됨.
UDP 전용 소켓(=datagram 소켓)
udp는 tcp와 달리 비연결지향임.

tcp 소켓의 핵심은 accept() 시스템 콜
socket() 시스템 콜
소켓을 만드는 시스템 콜, 미리 형태를 잡아두는 것이라고 이해하면 됨.
socket(domain, type, protocol):
domain: IPv4, IPv6중 무엇을 사용할지 결정
type: stream, datagram소켓 중 선택
protocol: 0,6,17중 0을 넣으면 시스템이 프로토콜을 선택하며, 6이면 tcp, 17이면 udp
int socket_descriptor;
socket_descriptor = socket(AF_INET, SOCK_STREAM, 0);
socket()의 리턴값은 파일 디스크립터임.
리눅스에서는 모든 것을 파일로 취급하며 소켓 역시 파일로 취급
웹서버 프로세스가 데이터를 전송하기 위해 write(), read() 시스템 콜을 사용 할때, 대상 파일의 파일 디스크립터를 파라미터로 전송하여 OS에게 어떤 파일에 데이터를 작성할지, 혹은 어떤 파일의 데이터를 요청할지 결정.
이때, 파일 디스크립터가 소켓의 파일 디스크립터인 경우, 소켓에 데이터를 작성(데이터 송신) 혹은 소켓의 데이터를 읽어들이는(데이터 수신)동작을 하게 되는것.
socket() 시스템 콜은 미리 IPv4통신을 위해 사용할지, IPv6 통신을 위해 사용할지, TCP를 사용할지 아니면 UDP를 사용할지 틀을 만들어두는 것이라 생각하면됨.
bind() 시스템 콜
bind(sockfd ,sockaddr, socklen_t)
sockfd : 바인딩을 할 소켓의 파일 디스크립터
sockaddr : 소켓에 바인딩할 아이피 주소, 포트번호를 담은 구조체
socklen_t : 위 구조체의 메모리 크기
#include <sys/socket.h>
#include <netinet/in.h>
int main() {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1) {
perror("Socket creation failed");
return 1;
}
struct sockaddr_in server_address;
server_address.sin_family = AF_INET; // IPv4 주소 체계
server_address.sin_addr.s_addr = INADDR_ANY; // 모든 가능한 IP 주소
server_address.sin_port = htons(80); // 포트 번호 80
if (bind(sockfd, (struct sockaddr *)&server_address, sizeof(server_address)) == -1) {
perror("Bind failed");
return 1;
}
// 바인딩 성공 처리 및 작업 수행
return 0;
}
bind() 시스템 콜은 생성한 소켓에 실제 아이피 주소와 포트번호를 부여하는 시스템 콜이며 OS에게 어떤 소켓에 아이피 주소와 포트번호를 부여할지 알려주기 위해 파라미터에 소켓의 파일 디스크립터를 포함함.
클라이언트는 통신시 포트번호가 자동으로 부여되기에 bind 시스템 콜은 서버에서만 사용됨.
listen() 시스템 콜 only for TCP
listen(sockfd, backlog)
sockfd : 소켓의 파일 디스크립터
backlog : 연결 요청을 받아줄 크기 = TCP의 백로그 큐의 크기
#include <sys/socket.h>
int main() {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1) {
perror("Socket creation failed");
return 1;
}
// ... 서버 소켓의 주소와 바인딩 설정 ...
int backlog = 10; // 최대 대기열 크기
if (listen(sockfd, backlog) == -1) {
perror("Listen failed");
return 1;
}
// 리스닝 성공 처리 및 연결 요청 처리
return 0;
}
listen() 시스템 콜은 연결지향인 TCP에서만 사용하며 파라미터로 받은 파일 디스크립터에 해당하는 소켓을 클라이언트의 연결 요청을 받아들이도록하며 최대로 받아주는 크기를 backlog로 설정한다
이 listen() 시스템 콜에서 설정하는 backlog의 크기가 TCP에서의 backlog queue의 크기다.
연결 요청을 받아들이는 방법
listen() 시스템 콜은 파라미터로 받은 backlog 크기만큼 backlog queue를 만드는 시스템 콜
서버측의 소켓은 listen()이후 대기 상태에서 클라이언트의 연결 요청을 받아주기 위해 backlog queue를 가진 채로 기다림.
실제로는 서버에 셀수 없이 많은 클라이언트가 요청을 보내게 되고 이 요청들은 모두 backlog queue에 저장됨.

accept() 시스템 콜
int accept(sockfd, sockaddr, socklen_t);
sockfd : 소켓의 파일 디스크립터
sockaddr : 선입선출로 빼온 연결 요청에서 알아낸 클라이언트의 주소
socklen_t : 구조체의 메모리 크기
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main() {
int server_socket = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_address;
server_address.sin_family = AF_INET;
server_address.sin_addr.s_addr = INADDR_ANY;
server_address.sin_port = htons(80);
bind(server_socket, (struct sockaddr *)&server_address, sizeof(server_address));
listen(server_socket, 5);
printf("Server: Waiting for client's connection...\n");
struct sockaddr_in client_address;
socklen_t client_addrlen = sizeof(client_address);
int client_socket = accept(server_socket, (struct sockaddr *)&client_address, &client_addrlen);
printf("Server: Accepted connection from %s:%d\n",
inet_ntoa(client_address.sin_addr), ntohs(client_address.sin_port));
// 3-way handshake의 나머지 두 단계 수행
char buffer[1024];
ssize_t bytes_received = recv(client_socket, buffer, sizeof(buffer), 0); // 클라이언트의 ACK 받기
if (bytes_received > 0) {
printf("Server: Received ACK from client.\n");
}
accept 시스템 콜은 backlog queue에서 syn을 보내와 대기중인 요청을 선입선출로 하나씩 연결에 대한 수립을 해줌.
파라미터를 보면 클라이언트의 아이피 주소, 포트번호를 받는데 이 값은 백로그 큐에서 가장 앞에있는 연결요청 구조체에서 알아내서 가져옴.
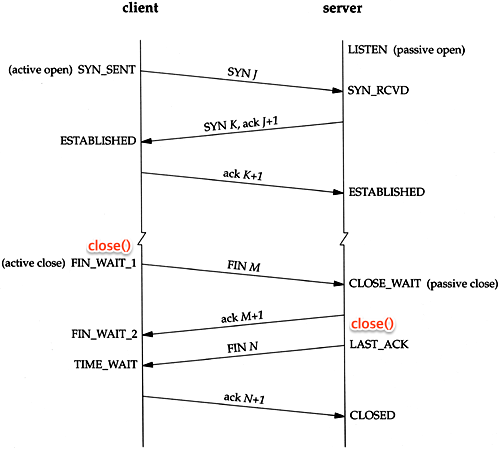
TCP 3-way handshake
TCP의 특징 : 연결지향, 신뢰성(=3way handshake)

클라이언트와 서버간의 서로 신뢰성 있는 통신을 위해 서로 준비가 되어있다라는걸 확인하는 과정
위 과정중 client가 보내는 SYN이 listen 상태인 서버의 소켓에 연결 요청을 보내는것
이후 과정은 accept 시스템 콜 이후 진행하여 최종적으로 established 상태를 수립하고 본격적인 데이터의 송/수신이 일어남.

사실 accept 시스템 콜 이후 곧바로 잔여 3-way handshake 이후 데이터 송수신이 일어나는것은 아님.
서버의 성능을 위해 또 하나의 테크닉이 들어가게됨.(멀티 프로세스 or 멀티 스레드)
하나의 프로세스인 서버가 수많은 클라이언트의 요청을 받는 상황에서, 백로그 큐의 가장 앞에 있던 클라이언트의 요청을 받고 응답까지 다 주고 다시 다음 요청을 받아준다면 엄청난 병목이 생김
(따라서 서버는 연결 요청을 받는 부분 따로, 이후 응답 주는 부분 따로 나눔)
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main() {
int server_socket = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_address;
server_address.sin_family = AF_INET;
server_address.sin_addr.s_addr = INADDR_ANY;
server_address.sin_port = htons(80); // 웹 서버 포트인 80
bind(server_socket, (struct sockaddr *)&server_address, sizeof(server_address));
listen(server_socket, 5);
printf("Server: Listening on port 80...\n");
while (1) {
struct sockaddr_in client_address;
socklen_t client_addrlen = sizeof(client_address);
int client_socket = accept(server_socket, (struct sockaddr *)&client_address, &client_addrlen);
if (fork() == 0) { // 자식 프로세스 <- 이 부분에 집중!
printf("Server: Accepted connection from %s:%d\n",
inet_ntoa(client_address.sin_addr), ntohs(client_address.sin_port));
// 3-way handshake의 나머지 두 단계 수행
// 여기서는 ACK를 보내는 과정만 간단히 보여줍니다.
sleep(1); // 실제로는 필요한 로직 수행
// 서버의 응답 전송
char response[] = "HTTP/1.1 200 OK\r\nContent-Length: 13\r\n\r\nHello, world!";
send(client_socket, response, strlen(response), 0);
printf("Server: Sent response to client.\n");
close(client_socket);
exit(0);
}
close(client_socket);
}
close(server_socket);
return 0;
}
위 코드에서 accept 시스템 콜에 대한 리턴을 받음
( == SYN 요청을 보낸 클라이언트가 적어도 하나 있어서 백로그 큐에 있었고 해당 클라이언트의 요청에 대한 이후 응답을 위해 새로운 소켓을 만들었다.)
fork() - 자식 프로세스 생성
리턴값 = 0 자식 프로세스, 0이 아님 = 원래 본인(부모) 프로세스
부모 프로세스는 연결 요청을 받아주고 자식 프로세스에게 나머지 일을 맡기고 다시 새로운 연결 요청을 받아줌
#include <stdio.h#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main() {
int server_socket = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_address;
server_address.sin_family = AF_INET;
server_address.sin_addr.s_addr = INADDR_ANY;
server_address.sin_port = htons(80); // 웹 서버 포트인 80
bind(server_socket, (struct sockaddr *)&server_address, sizeof(server_address));
listen(server_socket, 5);
printf("Server: Listening on port 80...\n");
while (1) {
struct sockaddr_in client_address;
socklen_t client_addrlen = sizeof(client_address);
int client_socket = accept(server_socket, (struct sockaddr *)&client_address, &client_addrlen);
if (fork() == 0 -> false ) {
실행안함
}
}
close(server_socket);
return 0;
}
자식 프로세스는 반면 부모 프로세스가 새로 만들어준 소켓을 이어받아 이후 남은 잔여 3-way handshake 수행 후 데이터 통신을 수행
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main() {
int server_socket = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_address;
server_address.sin_family = AF_INET;
server_address.sin_addr.s_addr = INADDR_ANY;
server_address.sin_port = htons(80); // 웹 서버 포트인 80
bind(server_socket, (struct sockaddr *)&server_address, sizeof(server_address));
listen(server_socket, 5);
printf("Server: Listening on port 80...\n");
while (1) {
struct sockaddr_in client_address;
socklen_t client_addrlen = sizeof(client_address);
int client_socket = accept(server_socket, (struct sockaddr *)&client_address, &client_addrlen);
if (fork() == 0 -> true) { // 자식 프로세스
close(server_socket);
printf("Server: Accepted connection from %s:%d\n",
inet_ntoa(client_address.sin_addr), ntohs(client_address.sin_port));
// 3-way handshake의 나머지 두 단계 수행
// 여기서는 ACK를 보내는 과정만 간단히 보여줍니다.
sleep(1); // 실제로는 필요한 로직 수행
// 서버의 응답 전송
char response[] = "HTTP/1.1 200 OK\r\nContent-Length: 13\r\n\r\nHello, world!";
send(client_socket, response, strlen(response), 0);
printf("Server: Sent response to client.\n");
close(client_socket);
exit(0); <-여기서 자식 프로세스가 종료됨
}
close(client_socket);
}
close(server_socket);
return 0;
}
멀티 스레드:
멀티 프로세스의 단점을 보완하기 위해 리눅스에서 등장한 기술, 멀티 프로세스의 단점을 보완한 것을 제외하고는 크게 다르지 않음.