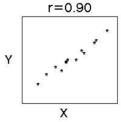
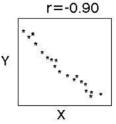
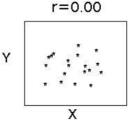
회귀분석(회귀 이론을 기초로 독립변수가 종속변수에 미치는 영향을 파악하여 예측모형을 도출하는 통계적 방법)의 시초는 아버지와 아들의 키 연관성 연구에서 부터 시작됌
아들의 키가 아버지의 키 수준으로 얼마나 회귀하는지 찾기 위한 연구
독립변수: 어떠한 현상을 설명할때 현상의 발생에 영향을 미치는 요인
종속변수: 독립변수의 영향에 따라 결정되는 요인
예측모형: 독립변수와 종속변수에 해당하는 자료를 모아 관계를 분석하고, 이를 예측할수있는 통게적 방법으로 정리한것
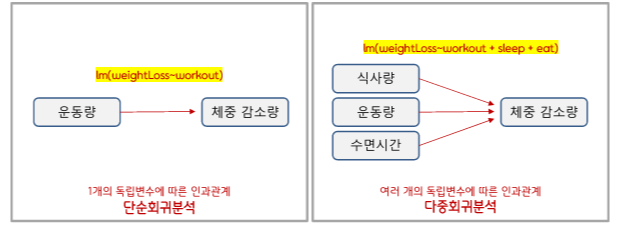
식사량 운동량 수면시간은 독립변수이고
체중감소량은 종속변수이다
회귀식 : 독립변수와 종속변수 사이의 관계를 수학식으로 표현
단순회귀 : 독립변수의 1개인 경우
다중회귀 : 독립변수가 2개 이상인 경우
로지스틱 회귀 : 종속변수의 값의 형태가 연속형 숫자가 아닌 범주형 값인 경우, 이를
분석하기 위해 사용하는 통계적 방법
분류 : 데이터로부터 어떠한 범주를 예측하는 작업
단순회귀분석 개념
독립변수(x)와 종속변수(y) 사이의 선형관계를 파악하여 예측에 활용하는 통계적 방법
독립변수와 종속변수에 대해 수집한 데이터를 활용하여, 인과관계를 가장 잘 설명하는
w와 b를 찾는 게 단순회귀분석의 목표
단순회귀식
y=wx + b (w, b는 상수)
x -> 독립변수(영향을 주는 값)
y -> 종속변수(영향을 받는 값)
w -> 단순회귀선의 기울기
b -> 단순회귀선의 절편(y축과 단순회귀선이 닿는 지점)
w의 값에따라서 기울기가 달라짐
(기존 mtcars 데이터를 통해, 차량 중량을 바탕으로 연비를 예측하는 모형 만들기)
data(mtcars)
plot(mpg~wt, data = mtcars) #차량 중량(x)과 연비(y) 간의 산점도를 통해 선형관계 확인
model <- lm(mpg~wt, mtcars) #회귀모형 생성하기
abline(model) #회귀선을 산점도 위에 표시
coef(model)[1] # 회귀결과 추출 : b값을 출력(37.28)
coef(model)[2] # 회귀결과 추출 : w값을 출력(-5.34)차량중량 – 연비 단순회귀분석 회귀식
𝑚𝑝𝑔 = −5.34 ∗𝑤𝑡+37.28
(새로운 차량 중량 값을 대입하여, 연비 값을 예측해보기)
b <- coef(model)[1] #b값 대입
w <- coef(model)[2] #w값 대입
wtSample <- 3.8 #예측하고자 하는 독립변수 대입
equation <- w * wtSample + b #회귀식 만들기
print(equation) #회귀식에 독립변수 대입한 결과 출력
회귀 모형 오차구하기
회귀모형의 예측값과 실제값의 차이
wtData <- mtcars[,"wt"] #전체 차량 중량 데이터 선택
mpgPred <- w * wtData + b #wtData를 회귀선에 대입하여 전체 차량 연비 예측값 도출
mpgData <- mtcars[, "mpg"] #전체 차량 연비 데이터 선택
compare <- data.frame(mpgPred, mpgData, mpgPred – mpgData)
#차량 연비 예측값, 차량 연비 실제값, 예측값과 실제값 간의 차이 계산값을 담은 데이터프레임 생성
colnames(compare) <- c("예상", "실제", "오차") #데이터프레임 열 이름 재정의
head(compare)
다중회귀분석: 여러 개의 독립변수(x)와 종속변수(y) 사이의 선형관계를 파악하여, 예측에 활용하는
통계적 방법
y=w1x1 + w2x2 + w3x3 + … wnxn +b (w, b는 상수)
x-> 독립변수(영향을 주는 값)
y-> 종속변수(영향을 받는 값)
w-> 회귀계수(회귀선의 기울기)
b-> 회귀상수(y축과 회귀선이 닿는 지점)
다중회귀분석의 주의사항!
독립변수와 종속변수간의 높은 상관관계
선택한 독립변수간에는 서로 낮은 상관관계를 보여야함 (다중공선성 문제가 발생가능)
독립변수 개수는 적을수록 유리
다중공선성은 독립변수들이 서로간에 강한 상관관계가 있어 상호 영햐을 줘서 종속변수 예측 값에 부정적인 영향을 주는 현상을 말함 -> 종속변수 추정에 오류를 발생시킬수있음
다중회귀분석
data(mtcars)
colnames(데이터프레임) <- c(“”, “”, “”,…)
• 데이터프레임 열 명칭 재설정
df <- data.frame(mtcars$wt, mtcars$disp, mtcars$hp)
#독립변수 데이터들을 바탕으로 DF 생성
colnames(df) <- c("중량", "배기량", "마력") #DF 열 명칭 재설정
plot(df, pch = 16, col = "blue", main = "산점도 매트릭스") #3:3 산점도 매트릭스 그리기
model <- lm(mpg ~ wt + disp + hp, data = mtcars) #다중회귀분석 예측모형 만들기
summary(model) #예측모형 결과 도출R-square는 다중선형회귀모형이 mpg를 얼마나 잘 설명하는지 나타냄. 0.65 이상이면 잘 설명하는 것으로 간주함.
stepAIC() 함수를 통해 유의미한 독립변수 만으로 회귀모형을 만드는 변수선택을 진행하여, 새로운 회귀모형을 만들고 최종 회귀식 도출
요약정리
회귀분석 이해
– 독립변수 / 종속 변수 / 예측모형
– 단순회귀 / 다중회귀
lm() 함수
– 회귀분석에 필수적인 함수
– lm(formula, data) / lm(y축 변수~x축 변수, 데이터프레임)
단순회귀분석
– 독립변수(x)와 종속변수(y) 사이의 선형관계를 파악하여 예측에 활용하는 통계적 방법
– y=wx + b (w, b는 상수)
data(데이터프레임)
plot(y축 변수~x축 변수, data=데이터프레임)
lm(y축 변수~x축 변수, 데이터프레임)
abline(회귀식l)
coef(회귀식) [1] b값 출력 [2] w값 출력
다중회귀분석
– 여러 개의 독립변수(x)와 종속변수(y) 사이의 선형관계를 파악하여,예측에 활용하는 통계적 방법
– y=w1x1+ w2x2+ w3x3+ …wnxn+b (w, b는 상수)
data(데이터프레임)
data.frame(데이터프레임$변수1, 데이터프레임$변수2, 데이터프레임$변수3)
colnames(뉴데이터프레임) <- c(변경할 문구)
lm(y축 변수~x축 변수1+x축 변수2+x축 변수3+...,, 데이터프레임)
library(MASS)
stepAIC(회귀식)
summary(회귀모델)