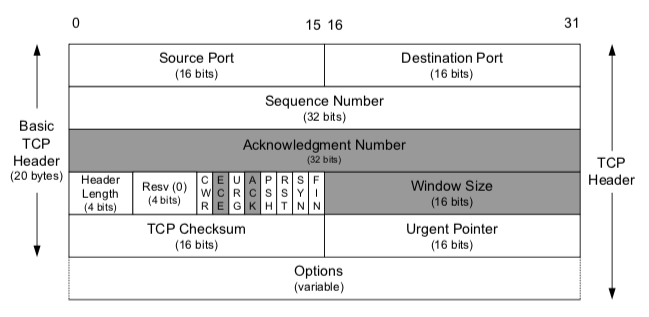
AWS 리전, 가용영역
리전이란?
aws에서 수많은 컴퓨팅 서비스를 하려면 당연히 대규모의 서버 컴퓨터를 모아놓을 곳이 필요하는데 이때 한곳에 몰아넣게 되면 2가지 문제가 생김
(자연재해 발생시 모든 서비스 마비, 모든 자원이 북미에 있다면 아시아지역에서의 서비스가 느려짐)
따라서 위 문제점 해결하기 위하여 자원을 여러곳에 분산시켜 놓은것
가용영역은 리전을 한번 더 분산시켜서 놓은것
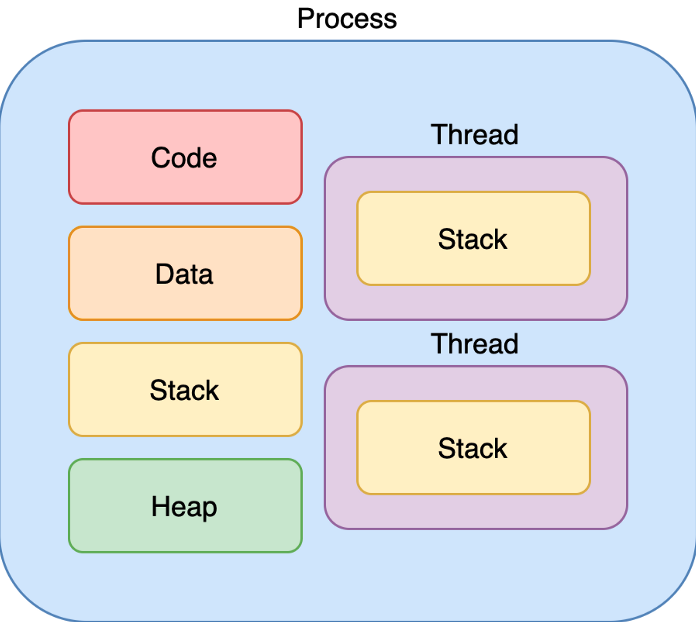
AWS VPC
서브넷
흔히 사용되는 IPv4의 주소 체계는 클래스를 나누어 IP를 할당한다. 하지만 이 방식은 매우 비효율적이다.
예를들어서 어떤 기관에 A클래스를 할당한다고 하면 16,777,214개의 호스트를 할당 할 수 있는데 이 기관이 100개의 호스트를 할당한다고 하더라도 16,777,114개의 호스트를 낭비하게 된다.
이러한 비효율성을 해결하기 위해서 네트워크 장치들의 수에 따라서 효율적으로 사용할 수 있는 서브넷이 등장하게 되었다.
IP 주소란?
Internet Protocol의 약자로 네트워크 통신을 할때 사용되는 프로토콜.
IP 주소를 사용하는 이유는 각각의 host들을 구분하여 데이터를 정확하게 송수신하기 위함.
IP 주소는 IPv4와 IPv6체계로 나뉨
IPv4

3자리 숫자가 4마디로 표기되는 방식.
각 마디는 옥텟이라고 명칭.
위 주소는 내부적으로 32비트로 처리됨(각 마디당 8비트)
예를들어서 192.168.123.123은 11000000.10101000.1111011.1111011로 표시됨.
IPv4는 한 옥텟당 256개(2의 8승)를 할당 할 수 있어서 4,294,967,296개의 주소를 만들수 있음(256의 4승) = 약 42억개
하지만 인터넷 환경이 발달함에 따라서 어마어마하게 많은 IP주소가 필요해져서 IPv4 주소 체계로는 IP주소를 할당하기에 힘들어졌음.
이때 새로운 주소 체계인 IPv6가 나오게됨.

IP 주소는 대역에 따라서 A,B,C,D,E 클래스로 나뉘는데 클래스를 구분함으로써 클래스내에서 네트워크 ID와 호스트 ID를 구분함.
A class : 대규모 네트워크 환경에 쓰이며, 첫번째 마디 숫자가 0~127 까지 사용됨
B class : 중규모 네트워크 환경에 쓰이며, 첫번째 마디 숫자가 128~191 까지 사용됨
C class : 소규모 네트워크 환경에 쓰이며, 첫번째 마디 숫자가 192~223까지 사용됨
D class : 멀티캐스팅용으로 잘 쓰이지 않는다.
E class : 연구 / 개발용 혹은 미래에 사용하기 위해 남겨놓은 클래스로 일반적인 용도로 사용되지않음.
A class는 하나의 네트워크가 가질수있는 호스트수가 가장 많은 클래스.

네트워크 영역은 앞 8비트가 차지하고 나머지 24비트는 호스트 영역
예를들어 18.123.123.123이라는 IP주소가 있다면 18은 네트워크 ID를 나타내고 123.123.123은 호스트 ID
첫번째 옥텟이 가질수 있는 범위는 0~127이고 1개의 네트워크 영역이 각각 가질수 있는 호스트 ID는( 2의 24승 )-2이다.
-2를 해준 이유는 시작주소는 x.0.0.0은 네트워크 주소로 사용하고 마지막 주소인 x.255.255.255는 브로드캐스트 주소로 사용되기 때문
예를들어서 13.x.x.x 네트워크 주소에서 호스트 영역을 할당한다고 하면 13은 네트워크 영역이고 x.x.x부분은 호스트 영역으로 0.0.0과 255.255.255를 제외한 13.0.0.1 ~ 13.255.255.254 까지 (2의 24승)-2 개를 할당할 수 있는 것이다.
B class는 중규모 네트워크에서 사용되는데 네트워크 영역은 앞의 16비트가 차지하고, 호스트 영역은 뒤 16비트가 차지한다.
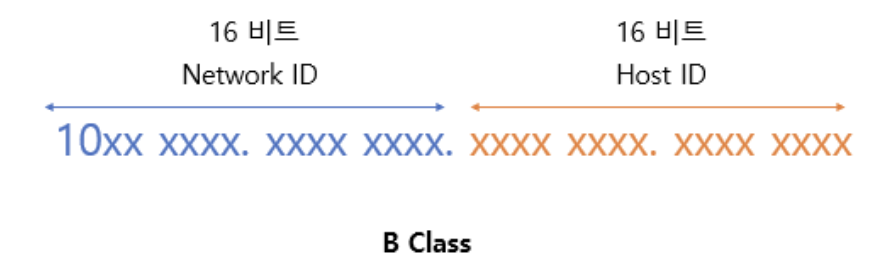
예를들어 151.123.123.123이라는 IP 주소가 있다면 151.123은 네트워크 ID를 나타내고 123.123은 호스트 ID를 나타낸다.
첫번째 옥텟의 범위는 128~191이고 1개의 네트워크 영역이 각각 가질수있는 호스트 ID는 (2의 16승) -2 개이다.
C class 는 소규모 네트워크에서 사용되며 네트워크 영역은 앞의 24비트가 차지하고 호스트 영역은 뒤 6비트가 차지한다.
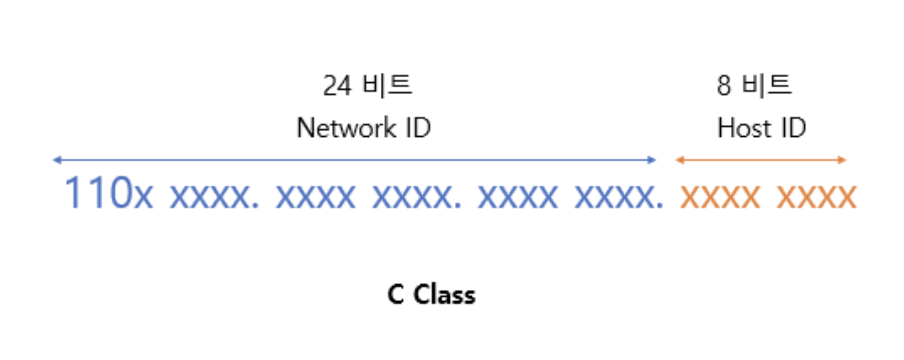
예를들어 201.123.123.123이라는 IP주소가 있다면 201.123.123은 네트워크 ID를 나타내고 121은 호스트 ID를 나타낸다.
첫번째 옥텟의 범위는 192~223이고 1개의 네트워크 영역이 각각 가질수 있는 호스트 ID는 (2의 8승) -2 개이다.
클래스 구분을 예시를 들어보면
132.12.11.4
클래스 : B
네트워크 영역 : 132.12
호스트 영역 : 11.4
10.3.4.1
클래스 : A
네트워크 영역 : 10
호스트 영역 : 3.4.1
203.10.1.1
클래스 : C
네트워크 영역 : 203.10.1
호스트 영역 : 1
IPv6
위에 IPv4 주소 체계만으로는 주소가 부족하여서 IPv6 가 나왔다고 말했는데, IPv6는 32비트 체계가 아닌 128비트 체계의 인터넷 프로토콜을 의미한다.

즉, 2^128 = 340,282,366,920,938,463,463,374,607,431,768,211,456 개의 주소를 할당할 수 있다.
16비트씩 8자리로 각 자리를 ':'로 구분한다.
여기서 문제는 아직까지도 IPv4에서 IPv6로의 전환이 완료되지않았다는 점이다.
아직 많은 라우터들이 IPv4를 사용한다.
IPv6로의 전환은 많은 시간과 비용이 들기 때문에 완료되기까지 적지않은 시간이 걸릴 것이다.
현재는 IPv4와 IPv6를 혼용해서 사용하는데 IPv4 라우터에서 tunneling이라는 방식을 사용해서 IPv6 데이터그램을 전송한다.
다시 서브넷으로 돌아와보자.
서브넷은 IP주소에서 네트워크 영역을 부분적으로 나눈 부분 네트워크를 뜻한다. 이러한 서브넷을 만들때 사용되는것이 서브넷 마스크이다.
즉, 서브넷 마스크는 IP 주소 체계의 네트워크 ID와 호스트 ID를 분리하는 역할을한다.

예를들어 C class는 기본적으로 앞의 24비트가 네트워크 영역, 뒤에 8비트가 호스트 영역으로 되어있는데, 이때 서브넷 마스크를 이용하면 원본 네트워크를 여러개의 네트워크로 분리할 수 있다. 이 과정을 서브넷팅이라고 한다.

각 클래스마다의 서브넷 마스크이다(D,E class는 사용하지않음)
이런 기본 서브넷 마스크를 사용하게되면 IP주소의 네트워크 id와 호스트 id를 구분할 수 있다.
IP 주소에 서브넷 마스크를 AND 연산하면 네트워크 ID가 된다.

예를들어 위에 사진처럼 저 C class의 IP주소가 있다고하면 C class의 기본 서브넷 마스크는 255.255.255.0이므로 and 연산을 해주면
네트워크 ID가 나온다. 이때 서브넷 마스크의 네트워크 ID 부분은 연속적으로 1이있어야하고 호스트ID부분은 0이 연속적으로 나와야한다.
예시의 IP주소를 보면 /24라는것이 붙어있는걸 볼 수 있을텐데 이것은 서브넷 마스크의 비트수(왼쪽에서부터 1의 갯수)를 나타낸다.
즉 /24는 해당 IP의 서브넷 마스크의 왼쪽에서부터 24개가 1이라는 것을 말해준다.
하지만 애초에 IP클래스들은 네트워크 영역이랑 호스트 영역이랑 나뉘어져있는데 굳이 서브넷 마스크가 왜 필요할까?
-> 서브넷팅을 하여 효율적인 네트워크 사용을 위해서
서브넷팅
서브넷팅은 IP주소 낭비를 방지 하기 위해서 원본 네트워크를 여러개의 서브넷으로 분리하는 과정을 뜻한다.
서브넷팅은 서브넷 마스크의 비트수를 증가시키는 것이라고 보면 된다. 서브넷 마스크의 비트수를 1씩 증가시키면 할당할 수 있는 네트워크가 2배수로 증가하고 호스트수는 2배로 감소한다.

예를들어서 C class 인 192.168.32.0/24를 서브넷 마스크의 비트수를 1 증가시켜서 192.168.32.0/25로 변경한다고 하면 위에 사진처럼
192.168.32.0/24는 원래 하나의 네트워크였지만 이때 할당 가능한 호스트의 수는 2의8승-2인 254개이다. 이때 서브넷 마스크의 비트수를 1 증가시켜서(서브넷팅) 192.168.32.0/25로 변경하게 되면 네트워크 id 부분을 나타내는 부분이 24비트에서 25비트로 증가하고 호스트 id를 나타내는 부분이다 8개비트에서 7개 비트로 줄어든다. 즉 할당 가능한 네트워크 수가 2개로 증가하고 각 네트워크당 할당가능한 호스트 수는 2의7승-2인 126개로 줄어든다 또한 서브넷 마스크가 255.255.255.128로 변한것을 확인할 수 있다.

211.100.10.0/24 네트워크를 각 서브넷당 55개의 Host를 할당할 수 있도록 서브넷팅 한다고 하자.
a) 서브넷 마스크를 구하시오.
호스트 id의 비트가 6개라면 2의 6승은 62개의 호스트id를 할당할 수 있으므로 충분하다.
그렇다면 32개의 비트중 26개가 네트워크 id(서브넷 마스크의 비트 갯수)이므로 1111111.11111111.11111111.11000000가 서브넷 마스크가 될것이다.
즉 255.255.255.192이다.
b) 서브넷의 개수를 구하시오.
--- 개념 추후 작성 ----
라우팅(Routing)
네트워크 세계에서 라우팅이란, 패킷에 포함된 주소등의 상세 정보를 이용하여 목적지까지 데이터 또는 메세지를 체계적으로 다른 네트워크에 전달하는 경로 선택 및 스위칭하는 과정을 이야기한다.
(= 라우팅이란 데이터가 전달되는 과정에서 여러 네트워크들을 통과해야하는 경우가 생기는데, 여러 네트워크들의 연결을 담당하고 있는 라우터 장비가 데이터의 목적지가 어디인지 확인하여 빠르고 정확한 길을 찾아 전달해주는것)
라우팅을 위해서 필요한 정보
- 출발지와 목적지의 네트워크 정보
- 목적지로 가는 모든 경로 : 출발지와 목적지 사이의 어떤 경로들이 있는지 알아야 최적경로 선택 가능
- 최적 경로 : 데이터 전달 위해서 모든 경로를 사용할 필요가 없기때문에 학습한 경로중 최적의 경로 하나 선택(이 경로 저장하는 곳은 routing table이라고 부르며 L3 장비는 이 table 정보를 사용하여 패킷 전달)
- 지속적인 네트워크 상태 확인 : 데이터 전달해주려는 경로 알지만 만약 그 경로가 다운된 상태라 사용하지 못하면 routing table에 저장된 경로로 전달이 가능한 상태인지 지속적으로 네트워킹 상태를 확인하여서 네트워크 정보를 항상 올바른 최신정보로 유지해야함.
라우팅 테이블
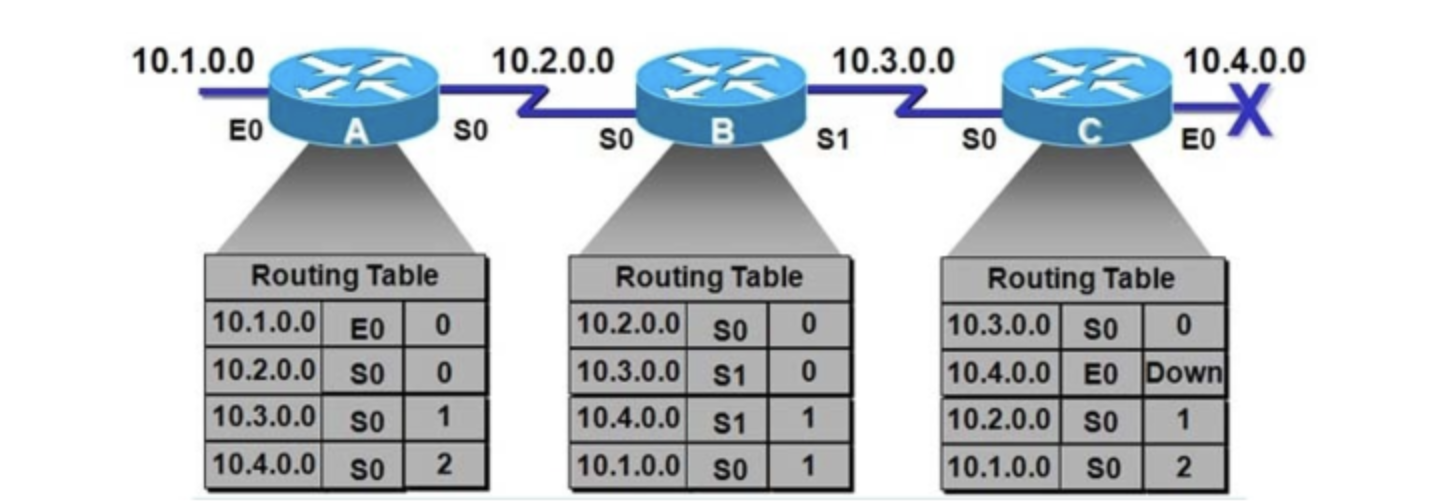
목적지까지 갈수있는 모든 가능성이 있는 경로들중에서 가장 효율이라고 판단되는 경로 정보는 패킷을 전달할때 바로 참고해서 사용할 수 있도록 따로 모아두는데 이 공간을 라우팅 테이블 이라고 한다.
라우터는 패킷의 목적지와 목적지를 가려면 어느 인터페이스로 가야하는지 자신의 라우팅 테이블에 가지고 있고, 패킷의 목적지 주소를 라우팅 테이블과 비교하여 어느 라우터에게 넘겨줄지 판단하게된다.
따라서 라우팅 프로토콜의 가장 중요한 목적이 바로 라우팅 테이블 구성이다.
정적 라우팅과 동적 라우팅
정적 라우팅
수동으로 라우팅 테이블을 만드는것
입력된 라우팅 정보가 수정하기 전에는 이전의 값이 변하지않고 고정된 값을 유지하며 라우팅 정보는 관리자가 수동으로 입력함.
장점: 관리자에 의한 라우팅 정보만 참조하기에 부담이 없어 빠르고, 안정적, 메모리 소모도 적음, 라우터간에 데이터 교환이 없으므로 대역폭을 절약할 수 있음. 외부에 정보 노출 안하기에 보안에도 좋음
단점: 각 경로를 수동으로 추가해주어야하기에 번거롭고, 정해진 경로에 장애가 발생할 경우 네트워크 전체에 장애 발생
동적 라우팅
접하는 라우터들이 라우팅 정보를 서로 교환하여 라우팅 테이블을 자동으로 만드는 것.
장점: 라우터가 서로 라우팅 정보를 주고받아 자동으로 라우팅 테이블을 작성하기 때문에 관리자는 초기 설정만해주면되어서 간단함, 네트워크의 규모가 커져도 자동으로 라우팅 테이블을 갱신하기 때문에 규모가 큰 네트워크에서 사용이 가능함.
단점: 다른 라우터들과도 계속 통신하기때문에 많은 대역폭 소비
CIDR
CIDR은 클래스없는 라우팅간 도메인 기법이다.
즉, 도메인간의 라우팅에 사용되는 인터넷 주소를 원래 IP 주소 클래스 체계를 쓰는거보다 더욱 능동의적으로 할 수 있도록 할당하여 지정하는 방식 중 하나.
IP주소 클래스를 배우면서 같이 배우는게 서브넷 마스크, 서브넷팅인데 서브넷팅과의 차이가 애매한데 서브넷팅 자체는 IP클래스에 국한되지않고 더욱 더 IP주소를 쪼개는 방식인데 이게 바로 클래스간 도메인 없는 라우팅 기법이다.
결론적으로는 서브네팅 ⊂ CIDR 이런 관계가 성립.
서브넷팅 뿐만 아니라 서브넷을 합치는 슈퍼네팅 역시 CIDR이다.
정리하자면 IP를 나누고 합치는 기술들을 다 CIDR이라고 보면 된다.
CIDR 표기법

cidr은 네트워크 정보를 여러개로 나누어진 sub-network들을 모두 나타낼 수 있는 하나의 network로 통합해서 보여주는 방법이라고 한다.
VPC
vpc는 기본적으로 가상의 네트워크 영역이기에 사설 아이피 주소를 가지게된다.

사설 아이피 대역은 10.0.0.0/8 172.16.0.0/12 192.168.0.0/24 이렇게 3개의 대역을 가지며, 하나의 vpc에는 위의 네트워크 대역, 혹은 서브넷 대역이 할당 가능하다.
10.0.0.0/8의 서브넷인 10.0.0.0/16도 vpc에 할당이 가능하다.
vpc는 실제로 사용시 vpc 자체에서도 서브넷을 나눠서 사용하게 된다.
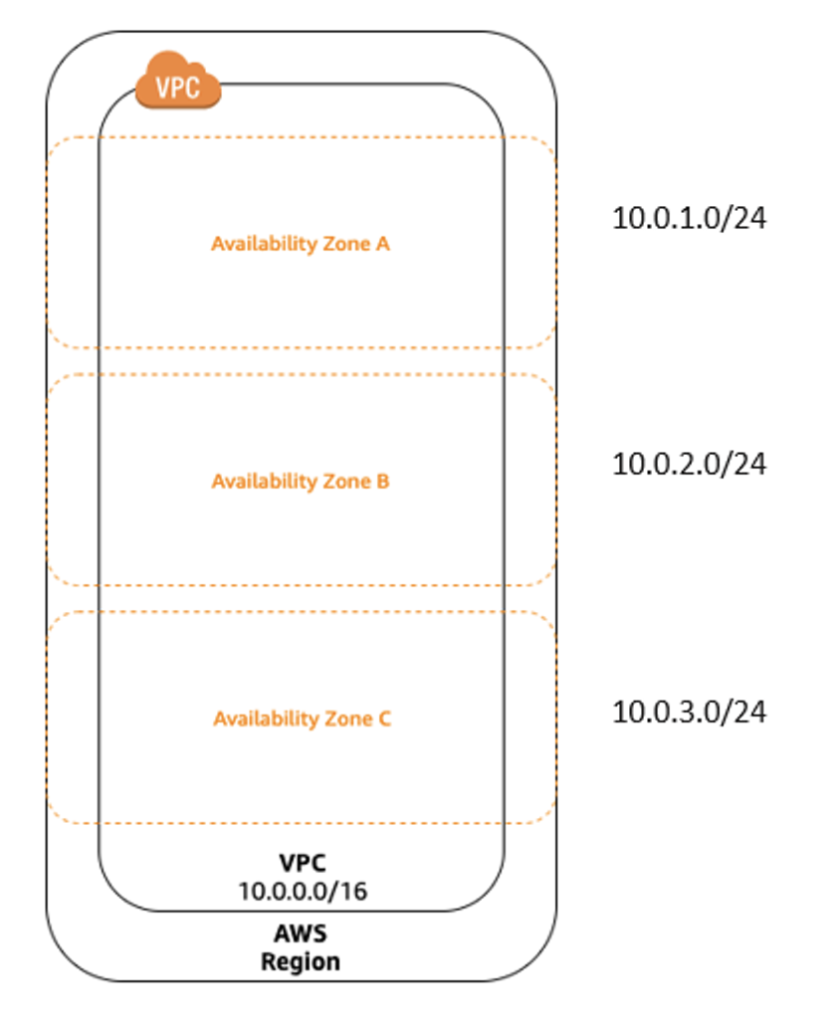
예시로 10.0.0.0/16의 아이피 주소를 VPC에 할당한 상황에서,
VPC를 원하면 다시 서브넷으로 나눠서 각각 서브넷을 원하는 가용영역에 배치하여 사용하게 됨.
이때 vpc의 서브넷 아이피 대역에서는 실제 네트워크와 달리 총 5개의 아이피 주소를 호스트에 할당 할 수 없음.
- 첫 주소 : 서브넷의 네트워크 대역
- 두번째 : VPC 라우터에 할당
- 세번째 : Amazon이 제공하는 DNS에 할당
- 미래를 위해 예약
- 브로드 캐스트 주소
이 5가지 항목을보고 VPC내부적으로 라우터가 있고 그렇다면 VPC 내부 서브넷끼리 통신이 된다는 것을 알아야함
VPC와 외부 통신
VPC가 어떻게 외부와 통신을 할까?
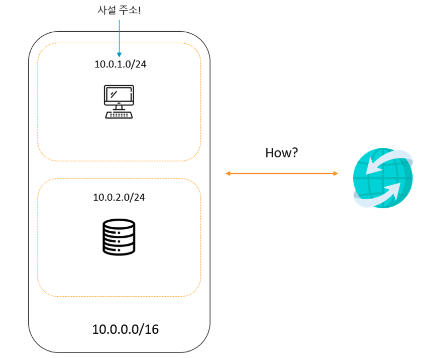
사설 아이피 대역은 공용 아이피 대역과 통신이 불가능하다 그런데 AWS로 인프라를 구축하면 통신이 되는 이유는 무엇일까?
Public subnet은 VPC 서브넷 중 외부와 통신이 월활하게 되는 서브넷 대역이고, Private Subnet은 외부와 통신이 되지않는 서브넷 대역이다.
Public subnet
AWS의 internet gateway 를 통해 해당 서브넷을 퍼블릭 서브넷이 되게 할 수 있다.
서브넷이 외부와 통신 할때, internet gateway를 거치게 하면 외부와 통신이 가능하게 한다.
이때 네트워크 패킷이 이동할때 특정 방향으로 가게한다 = 라우팅 인걸 알수 있다.
퍼블릭 서브넷으로 만들고 싶은 서브넷을 인터넷 게이트웨이를 통해 밖으로 나가도록 라우팅 테이블을 설정해주어야한다.

위 그림처럼 인터넷 게이트웨이를 만들고 라우팅 테이블에서
Destination : 0.0.0.0/0(모든 IP주소를 의미 = 외부 모든 아이피 = 밖으로 나갈때)
Target : 만들어둔 인터넷 게이트 웨이 식별자(해당 그림에서는 igw-1234567901234567)
이렇게 만들어진 라우팅 테이블을 내가 원하는 서브넷에 연결하여 퍼블릭 서브넷을 만들게 된다.
Destination: 10.0.0.0/16 = 목적지: 10.0.0.0/16(VPC 주소 = VPC로 들어올때)
Target: Local = (내부 VPC 라우터가 알아서 잘 보내줌)
Private Subnet
퍼블릭 서브넷과 달리, 아무런 조치를 취하지않아 (VPC가 기본적으로 사설 아이피) 외부와 단절된 서브넷
그럼 private subnet은 무슨 의미가 있을까?
사설 아이피 대역의 역할
1. 부족한 아이피 주소 문제를 완화
한국은 NAT이라는 서비스를 사용할 수 있는데 사실 공용 아이피 주소는 공유기에만 할당이되고, 공유기에 연결한 디바이스들은 사설 아이피 대역을 받게된다.

외부 인터넷은 공유기로 먼저 데이터를 보내고, 공유기는 포트를 통해 각 디바이스들을 구분하여 데이터를 보내주게 된다.
공유기의 80번 포트는 192.168.0.1 이 할당된 노트북
공유기의 8080번 포트는 192.168.0.2가 할당된 PC가 연결된 것
포트포 워딩이란?
하나의 공용 아이피 주소를 가진 공유기가 자신의 포트를 통해 올바른 사설 아이피 주소를 가진 디바이스에게 데이터를 주는 것.
2. 높은 보안성
외부 네트워크의 디바이스는 공유기 뒤에 사설 아이피를 가지고 있음.
이 숨어있는 디바이스로 직접 데이터를 절대 전송할 수 없고, 무조건 공유기를 거쳐야한다.
이때 공유기가 이상한 데이터는 버려준다면 이는 보안성 측면에선 좋다.
Private subnet을 사용하는 이유는 소중한 자원의 보호 때문입니다.
우리가 프로젝트를 진행하며 인프라를 구축할 때는 사실 Private subnet을 사용하지 않아도된다.
하지만 릴리즈 서버의 경우는 실제 고객의 데이터가 저장되는 데이터베이스를 보호해야하므로,
데이터베이스를 private subnet에 배치하는 것이 필요하다.
그럼 2가지 의문이 생기게되는데
1. private subnet에 두면 외부와 통신이 안되는데 그럼 데이터 베이스를 못쓰는거 아닌가?
2. 데이터베이스에 원격으로 접속하고싶은데 안되나?
이다.
1번은 데이터 베이스를 사용하는 (DB에 데이터를 저장하려는) EC2등과 같은 컴퓨팅 자원을 같은 VPC에 배치하면된다.(같은 VPC의 서브넷은 통신이 가능하다)
2번은 private subnet의 bastion host 개념을 이해하면되는데
릴리즈 인프라에서 사용될 데이터베이스를 보호하기 위해서 private subnet에 배치하였고, 실제로 데이터가 잘 저장이 되었는지 mysql workbench 혹은 datagrip으로 원격 접속하여 직접 눈으로 편하게 확인하고싶은데 database는 private subnet에 위치하여 데이터그립으로는 절대 원격접속이 안되는 상황이다. 이럴 경우 private subnet과 같은 VPC에 존재하는 public subnet의 도움을 받으면 된다.
이때 private subnet의 자원에 접속이 되도록 도와주는 호스트를 bastion host라고 한다.
실제로 데이터그립으로 private subnet의 데이터 베이스에 원격 접속을 하기 위해서는 SSH 터널링이라는 기술이 필요하나, 데이터그립에서 아주 쉽게 설정이 가능하다.